Review 2
Linear Regression¶
Regularization¶
Motivation
In the example of usage of basis function, we found higher-order polynomial fits data better but may fit noise and bring very large coefficients.
Hence we have a penalty of the coefficients, we call these methods "Regularization".
- \(L_1\)-Regularization
- \(L_2\)-Regularization
Where \(\lambda\) is a positive hyperparameter.
The Sparse Solution¶
What is Sparse Solution
The Sparse solution is the solution with more zero elements
From the above disscussion, it is clear that the regularization method produce more sparse solution.
Question
Which regularization method produce more sparse solutions?
In the vision of mathematics, all norms induced by the metric in Eucildean space are "equivalent" ?
The equivalence of norms is in the meaning of "metric", but here we are considering the "sparsity" i.e. the number of zeros in the solution vector.
We need a metric of sparsity.
\(L_0\) norm
\(\Vert x \Vert_0 := \#(\text{number of zeros in } x)\)
But the \(L_0\) norm is too difficult to compute, we need to find the best approximation. At the same time, we hope the approximation is easy to compute and have some good properities.
Theorem
\(L_1\) norm is the best convex approximation of \(L_0\) norm.
Linear Classification¶
Design of the Loss function¶
In the part of linear regression, the loss function is square loss function. In the classification task, the label \(y_i \in \{0, 1\}\),
If we still use the square loss function, the continuous output \(h_w(x_i)\) will be discretize to \(\{0,1\}\).
To map the output of \(h(x)\) to \([0,1]\), we can use the sigmoid function.
$$ \sigma(t) = \frac{1}{1 + e^{-t}} $$ And we can view the value \(\sigma(h(x)) = p(y = 1\mid x)\) as the probability to label \(x\) as \(y= 1\)
Review the knowledge of Cross-Entropy Loss.
Cross-Entropy Loss
We have a unknown distribution \(P\) and now we want to approximate it by another distribution \(Q\). In this process, we need a metric of the performance of the approximator.
In the information theory, we have a concept of relative entropy.
We call the first item cross entropy.
Hence we have the so-called cross entropy loss function.
Another kind of view: the negative log probability of success classification.
For the sake of preventing weights from diverging on linearly separable data, we can use the trick of regularization, such as \(L_1\), \(L_2\).
Another motivation is to get the unique solution in the linear separable training data.
Now, we found that the Loss function doesn't have analytic solution, we choose optimization methods to get a better solution.
From Binary-class to Multi-class¶
Prologue: the categorical distribution
Model an experiment with taking \(K\) different possibilities coded.
The notion
In a sence, the categorical distribution is a generalization of Bernoulli distribution.
To implement multi-class classification, we use multi weight vector to get different score and normalize them to get a categorical distribution.
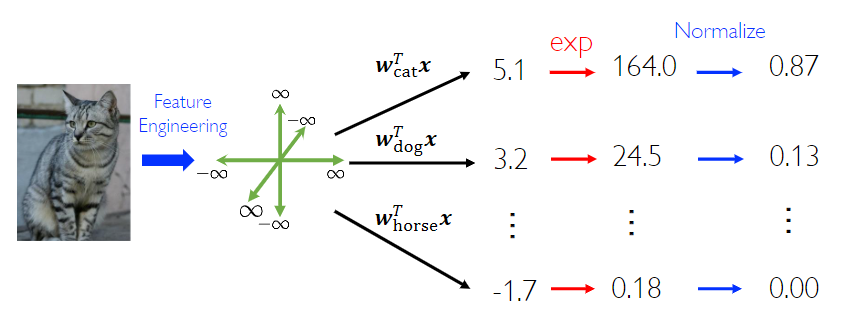
The key is use Softmax function to finish the normalization.
SVM¶
Hard SVM¶
Motivation
How to choose the best hyperplane of a classification task?
(for linear separable data)
The key concept of Support vector machine is the "Margin"
Margin
Twice of the distance to the closest points of either class.
Equivalently, margin is twice of the largest noise that can be tolerated by the classifier.
The target is
- largest margin
- Correctly classify all data points
Mathematically, optimize the SVM model is a constrained optimization problem.
How to compute margin?
Now let us take some math derivation.
we have a hyperplane \(w\cdot x + b = 0\) in Eucildean space, consider the points distributed in the two sides of this hyperplane.
In one side, for point \((x_i, y_i)\) we can get the inequality \(w \cdot x_i + b > 0\),in another size, naturally, \(w \cdot x_i + b < 0\)
In space analytic geometry, we have the formula to calculate the distance between a point and a hyperplane
Here we take the label \(y_i = \pm 1\).
Tune the norm of \(w\), such that the point closest to the classifier lies on the hyperplanes \(w \cdot x + b = \pm 1\)
At this time, we found the margin is
The optimization of the margin can be equivalently transformed to
Now, this is a convex optimization problem!
For separable to non-seperable¶
Instead of constraining all data points to be correctly classified, we allow some points on the wrong side of the margin.
Obviously, the number of the wrong classified point should be small. We introduce the concept of slack variables to solve this problem
The mathematical formalization following
The item \(\xi_i\) is called "slack variables".
In the part of constrains, we found
i.e.
Define the Hinge Loss function
The Goal of optimization can be rewrite to
Surrogate
The hinge loss function can be substituted by other functions to get better mathematical properities
- Exponential loss: \(l_{\exp}(x) = \exp(-x)\)
- Logistic loss: \(l_{\log}(x) = \log(1 + \exp(-z))\)
Different Views
We can introduce the soft SVM without the concept of slack variables.
We can count the number of wrong classified points and add them into the loss function as a item with a coefficient.
Where the \(l_{0/1}\) is the "0/1 loss function".
But this function is bad in math, we can introduce the concept of "Surrogate Loss" to substitute this function.
Interlude: Generalization¶
Look closely at the formula for Soft-SVM
- The first item is the loss caused by the model itself
- The second item is the loss on the training data set
We introducte the general form
Where the \(f\) is the so-called "model".
- The first item is called "Structural risk"
- The second item is called "Empirical risk"
- \(C\) is a hyperparameter used to trade-off between these two item.
Note
We can think the \(\Omega(f)\) as a "Regularization" item. It is used to cut the hypothesis space and introduce the prior knowledge to decrease the risk of overfitting.
The Dual Problem Theory and The Solution of SVM¶
Now we use the Lagrange method to directly solve the optimization of Soft-SVM.
The Lagrange function
Then let the partial derivatives of \(w, b, \xi\) equal to \(0\), we get the relation
Substitude \(w, b, \xi\) in the Lagrange function, we can get the dual problem of the original problem.
From linear to non-linear¶
Recall: We use the basis function to bring nonlinearity in the linear Regresssion models.
The idea is do some transform on the original feature space, then calculate the Regression problem in the new (maybe better) feature space.
Here we will do the same, perform some transform on the feature space and then calculate the optimization problem.
From the result previous section, If we have the transformation \(\phi\),the result will be
But the construction of \(\phi\) is difficult, we try to directly construct \(K(x, y)\), such that there exisit \(\phi\) and \(K(x,y) = \phi(x) \cdot \phi(y)\)
Reproducing kernel Hilbert space
First, let's introduce some definitions.
Evaluation functional
let \(\mathcal{H}\) be a Hilbert space of functionals \(f: \mathcal{X} \to R\), fix \(x \in \mathcal{X}\), \(\delta_x : H \to \mathbb{R}\), \(\delta_x := f \to f(x)\) is called the (Dirac) evaluation function.
Reproducing kernel Hilbert space, RKHS
If \(\delta_x\) is continuous, then \(H\) is a Reproducing kernel Hilbert space, RKHS
Reproducing Kernel
\(\mathcal{H}\) is a Hilbert space of functaionals \(f: \mathcal{X} \to \mathbb{R}\). If function \(k : \mathcal{X} \times \mathcal{X} \to \mathbb{R}\), satisfying
- \(\forall x \in \mathcal{X}\), \(k(\cdot, x) \in \mathcal{H}\)
- \(\forall x \in \mathcal{X}\), \(\forall f \in \mathcal{H}\), \(<k(\cdot, x), f>_\mathcal{H} = f(x)\)
Then we call \(k\) a reproducing kernel.
It is easy to prove: if there exist a reproducing kernel in a Hilbert space \(\mathcal{H}\), then it is unique.
The following theorem shows the relation between RKHS and Reproducing kernel.
Theorem
If there exist a Reproducing kernel, then we have
A linear functional is continuous if and only if it is bounded.
If \(\mathcal{H}\) is a Hilbert space, by the Riesz repersentation theorem.
Kernel
$k: \mathcal{X} \times \mathcal{X} \to \mathbb{R} $ if there exist \(\phi: \mathcal{X} \to \mathcal{H}\) s.t.
Then \(k(x, y)\) is a kernel.
Remark: \(k(x_i, x_j)\)